
Bouw schaalbare dataplatformen en neem technische beslissingen die impact maken bij toonaangevende organisaties.
Een baan als Data Engineer bij Digital Power
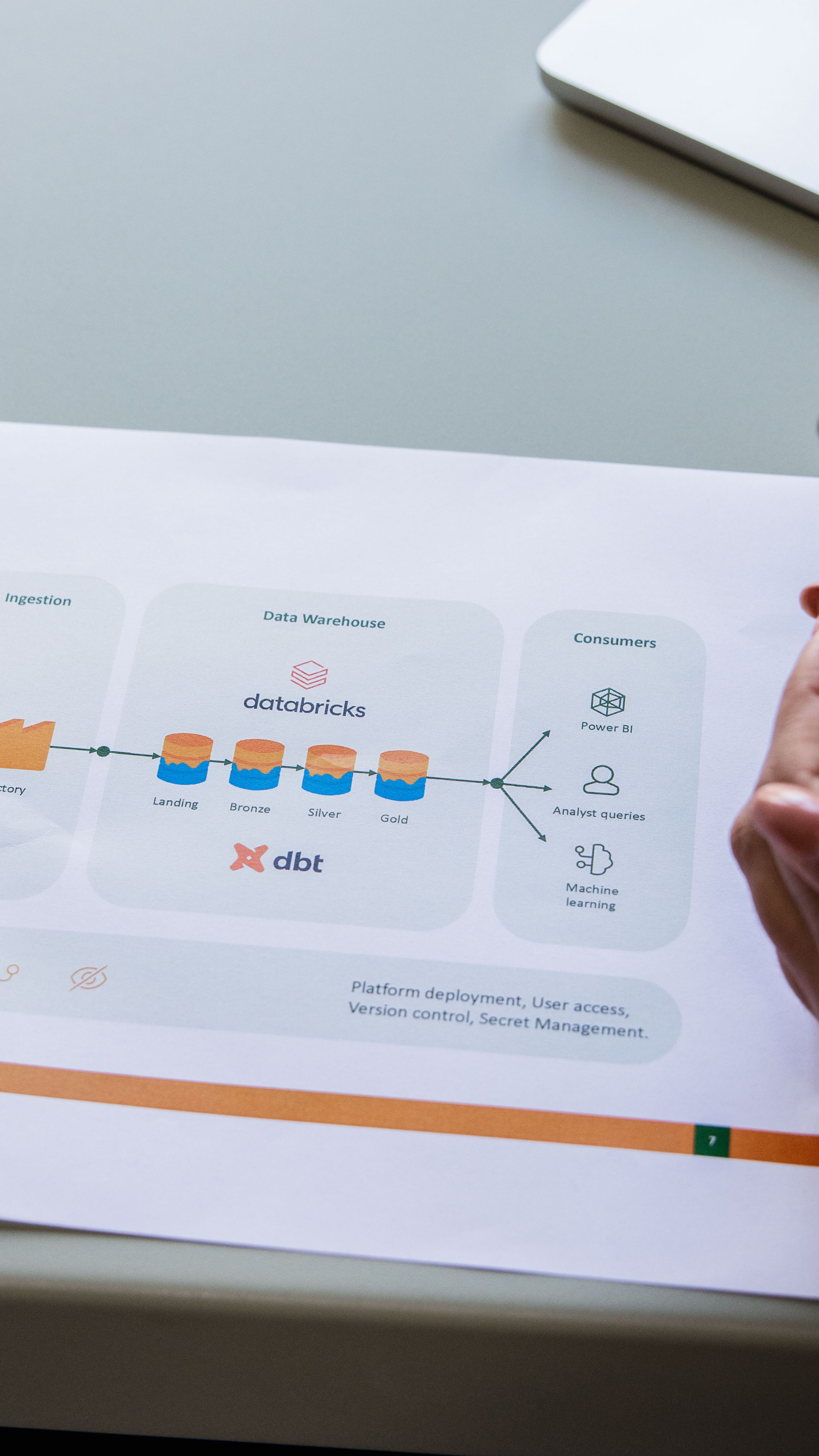
Bij Digital Power werk je aan data-oplossingen die een kernrol spelen in de organisatie van onze klanten. Je werkt dagelijks met moderne technologieën zoals Airflow, Kafka, Docker, Python en Databricks. Wil je je verder verdiepen in AI, dan is daar volop ruimte voor: van het ontwikkelen van AI-agents tot het inrichten en implementeren van Machine Learning Operations tooling.
Je werkt voor organisaties zoals Ikea, Bol en Heerema, maar ook voor start-ups, NGO’s en overheden. Naast je klantopdracht ben je onderdeel van onze interne community, waar kennisdeling, standaardisatie en innovatie centraal staan.











Wie we zoeken
Passie voor data
- Je denkt verder dan alleen code. Je begrijpt wat de business nodig heeft en vertaalt dit naar schaalbare technische oplossingen.
- Je voelt je verantwoordelijk voor het ontwerpen en onderhouden van dataplatformen en neemt hierin het voortouw.
- Je hebt oog voor stakeholdermanagement en stemt jouw oplossingen zorgvuldig af op zowel technische als zakelijke randvoorwaarden.
De nodige ervaring
- Minimaal 3 jaar ervaring als (cloud) Data Engineer
- Ervaring met datawarehousing, streaming data, MLOps en/of AI-toepassingen in productie
- Past Software Engineering principes en best practices toe in alles wat je bouwt
- Ontwerpen en implementeren van dataplatformen op AWS, Azure of Google Cloud Platform, met oog voor security, reliability, scalability en maintainability
- Ervaring met data-opslagtechnieken zoals data lakes, datawarehouses en SQL/NoSQL databases
- Kennis van DevOps-processen en tooling, zoals CI/CD pipelines en Terraform
- Ervaring met tools als Apache Airflow, Databricks, Snowflake, dbt, (Py)Spark en Scala
What else?
- Je hecht veel waarde aan het delen van je kennis
- Je vindt het belangrijk om op de hoogte te blijven van ontwikkelingen in je vakgebied
- Je beheerst de Nederlandse en Engelse taal goed in woord en geschrift
- Je krijgt goede energie van onze ‘werken bij’ pagina
- Een afgeronde hbo- of wo-opleiding
Wat we bieden
- Een salaris van € 4.285 – € 7.080 bruto per maand, afhankelijk van kennis en ervaring
- Ruimte om collega’s te begeleiden in hun ontwikkeling en bij te dragen aan interne projecten
- Een eigen leeromgeving in AWS, Azure en GCP
- Flexibele werktijden en een opleidingsbudget
- Kijk hier wat we je allemaal nog meer bieden
Wil jij dit soort Data Engineering uitdagingen aangaan?
Hoe ziet jouw dag eruit?
Je begint de dag met een kop koffie en een overzicht van je lopende werkzaamheden. Tijdens de stand-up met je projectteam bespreek je de voortgang, denk je mee over architectuurkeuzes en help je collega’s verder met inhoudelijk advies.
Daarna ga je zelf aan de slag. Voor deze opdracht rol je een MLOps-platform uit en ben je de CI/CD nog aan het debuggen voordat de proof of concept kan worden opgeleverd. Je stemt je voortgang af met stakeholders, zowel binnen Digital Power als bij de klant.
In de middag neem je bewust even afstand. Een lunch, een wandeling of focuswerk vanuit huis. Flexibiliteit is bij ons geen extraatje, maar de standaard.
Later op de dag spar je met collega’s over technische standaardisatie voor toekomstige projecten. Je sluit af met een pull request voor het klantproject en geeft een update aan je product owner.
Je werkt afwisselend bij de klant, thuis of op kantoor in Amsterdam of Den Bosch. Met ov, leaseauto of deels remote richt je je werkweek flexibel in, zolang je klant en je team op je kunnen bouwen.
Meer weten over deze functie?
Tsovik vertelt je graag meer over ons bedrijf, ons team en de uitdagingen die we je kunnen bieden.

Corporate Recruiter020 308 43 9006 15 26 47 64tsovik.gasparjan@digital-power.com
Benieuwd hoe het is om bij Digital Power te werken?
We zetten alle belangrijke vragen én antwoord voor je op een rij.
bekijk onze FAQ

