Efficiënter werken dankzij migratie naar Databricks
Het Kadaster
- Klantcase
- Data Engineering
- Dataconsultancy
- B2B
- Data warehousing



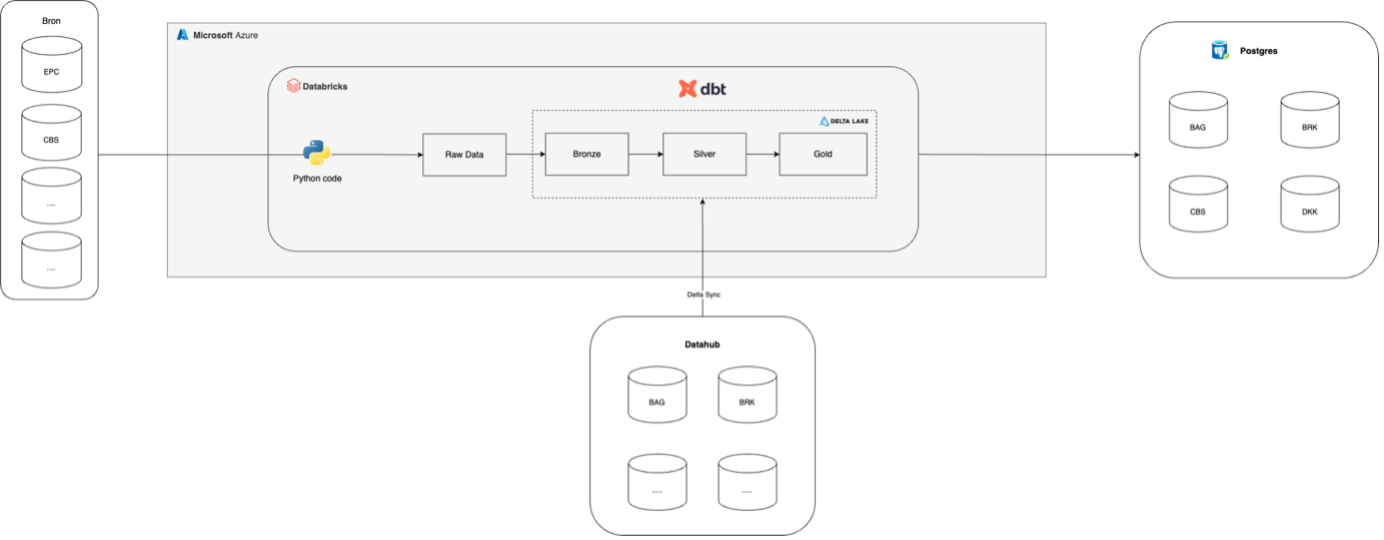
Het Kadaster beschikt onder andere over complexe (geo)data van al het vastgoed in Nederland. Alle data wordt opgeslagen en verwerkt via een on-premise data warehouse in Postgres. Voor het onderhoud van dit warehouse zijn ze afhankelijk van een IT-partner. Het Kadaster wil kosten besparen en efficiënter gaan werken door te migreren naar een Databricks-omgeving. Ze vroegen ons te helpen bij de implementatie van dit data lakehouse in Microsoft Azure Cloud.
Aanpak
Samen met een intern techteam brachten we een aantal bestaande pipelines in kaart. We keken welke data er al beschikbaar was in Databricks via de Datahub en welke data we zelf konden inladen met behulp van Python code. Op basis hiervan definieerden we een aantal use cases waarvoor we vervolgens de Databricks structuur uitdachten. Zo maakten we gebruik van een Medallion Architecture en het dbt framework voor datatransformaties binnen Databricks. Stapsgewijs werkten we de use cases steeds verder uit tot het punt waarop ze de Postgres set-up konden vervangen.
Het Kadaster houdt onder andere bij of een woning een appartement, tussenwoning, hoekwoning, twee-onder-een-kap of vrijstaand huis is. Om dit te doen, wordt er gekeken hoe objecten zich tot elkaar verhouden op een kaart. Als je hiervoor alle woningen in Nederland met elkaar vergelijkt, is dit een zeer zware berekening. We deelden daarom de kaart van Nederland op in vakjes met elk een eigen index en vergeleken de woningen binnen die vakjes met elkaar. De benodigde berekening draait hierdoor in een paar uur in plaats van een hele dag. Een mooie efficiencyslag in zowel tijd als kosten.
We focusten ons op specifieke use cases die uitgerold kunnen worden voor alle teams binnen het Kadaster. Tijdens de uitwerking waren we daarom continu in gesprek met de cloudarchitecten van het Kadaster. We deelden best practices en zetten de data klaar voor de eindgebruikers. Dit zijn voornamelijk analisten die inzichten leveren aan klanten van het Kadaster. Om intern draagvlak te creëren en mensen enthousiast te maken voor het nieuwe platform, organiseerden we kennissessies.
Resultaat
Een aantal use cases is uitgewerkt en opgezet in Databricks. Deze vormen een blauwdruk voor de migratie van andere processen. We hielpen het Kadaster de migratie van hun infrastructuur naar de cloud te versnellen. De onderdelen die we opzetten in Databricks, kunnen vervolgens uitgezet worden in Postgres. Zo kan het Kadaster steeds meer kosten en tijd besparen.
Het verwerken van geodata op Databricks is een niche. Samen met Kadaster waren we pioniers op dit vlak: we moesten uitzoeken hoe je het efficiënt kan doen. In de Postgresomgeving waren veel geotransformaties standaard beschikbaar via Postgis, maar in Databricks zijn deze functionaliteiten nog in ontwikkeling. We maakten gebruik van de open-source extensie Mosaic en moesten gedurende het project vaak uitzoeken hoe we dezelfde transformaties konden doen in Databricks.
Belangrijk hierbij was dat we de organisatie meenamen in wat er al kan en wat er in de toekomst mogelijk wordt. We leidden het interne team op in de nieuwe werkwijze en leerden ze welke softwareprincipes we gebruikten in het ontwikkelproces.
Om ervoor te zorgen dat de kennis geborgd werd binnen het team, zetten we verschillende documentatiepagina’s op binnen de interne wiki-omgeving. Daarnaast gaven we tijdens het gehele project trainingen op het gebied van Python, dbt en Databricks om het kennisniveau van het team te verhogen.
1x per maand data insights, praktijkcases en een kijkje achter de schermen ontvangen?
Meld je aan voor onze maillijst en blijf 'up to data':