Working more efficiently thanks to migration to Databricks
The Kadaster
- Customer case
- Data consultancy
- Data Engineering
- B2B
- Data warehousing



The Kadaster manages complex (geo)data, including all real estate in the Netherlands. All data is stored and processed using an on-premise data warehouse in Postgres. They rely on an IT partner for maintaining this warehouse. The Kadaster aims to save costs and work more efficiently by migrating to a Databricks environment. They asked us to assist in implementing this data lakehouse in the Microsoft Azure Cloud.
Approach
Together with an internal tech team, we mapped out existing pipelines. We assessed what data was already available in Databricks via the Datahub and what data we could load ourselves using Python code. Based on this, we defined several use cases for which we then designed the Databricks structure. We utilised a Medallion Architecture and the dbt framework for data transformations within Databricks. Step by step, we further developed the use cases until they could replace the Postgres setup.
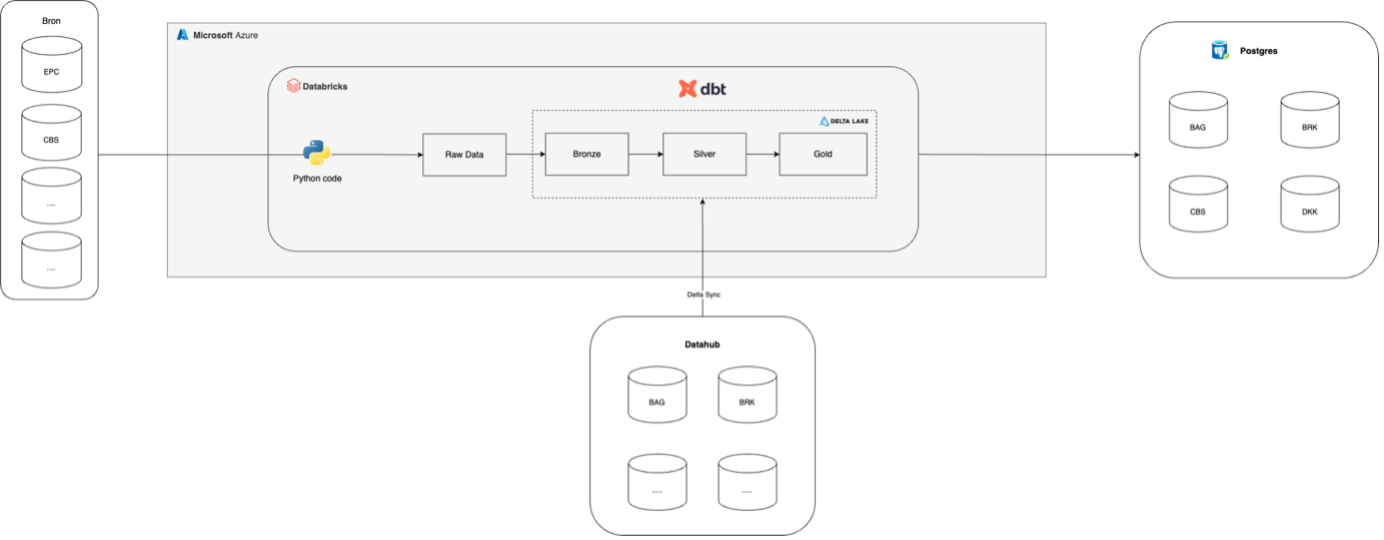
The Kadaster keeps track, among other things, of whether a property is an apartment, terraced house, corner house, semi-detached house, or detached house. To do this, the relationship between objects on a map is examined. Comparing all properties in the Netherlands in this way involves heavy calculations. Therefore, we divided the map of the Netherlands into grid squares, each with its own index, and compared the properties within those squares. This calculation now runs in a few hours instead of a whole day, a significant efficiency gain in both time and costs.
We focused on specific use cases that could be rolled out to all teams within the Kadaster. During implementation, we were in constant communication with the Kadaster's cloud architects. We shared best practices and prepared the data for end-users, primarily analysts providing insights to the Kadaster's clients. To create internal support and enthusiasm for the new platform, we organised knowledge-sharing sessions.
Result
Several use cases have been developed and set up in Databricks, serving as a blueprint for migrating other processes. We helped accelerate the Kadaster's migration of their infrastructure to the cloud. The components we set up in Databricks can then be replicated in Postgres, allowing the Kadaster to save more costs and time gradually.
Handling geodata on Databricks is a niche area. Together with the Kadaster, we were pioneers in this field, figuring out efficient methods. While many geotransformations were readily available in the Postgres environment via Postgis, these functionalities are still in development in Databricks. We utilised the open-source extension Mosaic and often had to figure out how to perform the same transformations in Databricks throughout the project.
It was crucial to involve the organisation in what is currently possible and what will be possible in the future. We trained the internal team in the new processes and taught them the software principles we used in the development process.
To ensure knowledge was retained within the team, we created various documentation pages within the internal wiki environment. Additionally, we provided training throughout the project on Python, dbt, and Databricks to enhance the team's knowledge level.
Want to know more?
Joachim will be happy to talk to you about what we can do for you and your organisation as a data partner.
Commercieel Manager Data Engineering+31(0)20 308 43 90+31(0)6 23 59 83 71joachim.vanbiemen@digital-power.com
Receive data insights, use cases and behind-the-scenes peeks once a month?
Sign up for our email list and stay 'up to data':