Reliable reporting using robust Python code
NDW
- Customer case
- Data Engineering
- Data consultancy
- B2B



The National Road Traffic Data Portal (NDW) is a valuable resource for municipalities, provinces, and the national government to gain insight into traffic flows and improve infrastructure efficiency.
NDW receives many requests for reports from its partners: the municipalities, provinces and the national government. The requests mainly concern insight into traffic flows in order to organise infrastructures more efficiently. Consider, for example, congestion on highways, pedestrian paths and bicycle paths.
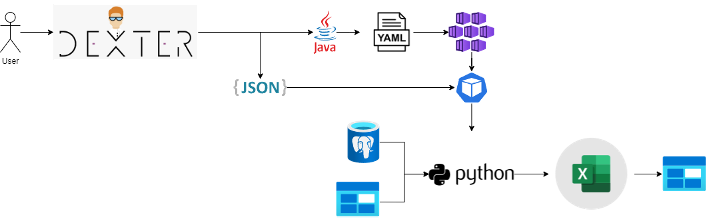
Examples of data that could be included in a report: what is the speed and length of vehicles on a highway, how long does someone have to wait at a bicycle traffic light, and how many people pass a certain point? NDW's partners can request these reports via Dexter, an online platform.
NDW collects the data itself and wants to offer this data to the end user in a usable form. They wanted to simplify this process. The company used Python and they enlisted the help of our Data Engineers to write the code. We have been a data partner of NDW since 2018. We help them by deploying Python developers in NDW's DevOps teams to make the data available for reports.
Approach
The approach consisted of two phases: the start-up phase and the production phase.
Start-up phase: we helped NDW create reports and wrote the code in Python. As a result, data was automated, collected, transformed and aggregated. We delivered the reports in Excel so that government specialists could edit the data themselves. In addition, NDW partners could easily view the reports through Excel.
Production phase: in the production phase, we made the reports future-proof and optimised the manageability and scalability of the Python code. We identified weak spots and properly accounted for them in the code. We also identified bottlenecks in terms of speed and error sensitivity. The optimisations made the entire process faster and less prone to errors. This has increased the data quality and reliability of the reports.
One example of optimisation is speeding up search results: when an NDW partner requests a report, several processes run in the background that pre-calculate the data. Thanks to the robust code, we quickly retrieve the information and present it to the user.
Techniques used
To create these reports, we combined various techniques. We stored the used data within Microsoft Azure’s Cloud environment, both on Blob Storage and in PostgreSQL databases. When a user requests a report, a Python job is created on the Kubernetes cluster. The script retrieves the data from the aforementioned sources, performs the transformations, and puts the requested reports in an Excel report. The user can then download them.
Results
NDW is now better equipped to provide fast, reliable reports with high data quality to its partners. The data processing processes are easier to manage because the code is better structured and more efficient. This has made the work more easily transferable to other Python developers.
Are you looking for a partner that can help you write Python code? Digital Power is the expert in the market and can do this for you!
Want to know more?
Joachim will be happy to talk to you about what we can do for you and your organisation as a data partner.
Commercieel Manager Data Engineering+31(0)20 308 43 90+31(0)6 23 59 83 71joachim.vanbiemen@digital-power.com
Receive data insights, use cases and behind-the-scenes peeks once a month?
Sign up for our email list and stay 'up to data':