A standardised way of processing data using dbt
Dutch webshop
- Customer case
- Data Engineering
- Data consultancy
- Analytics Engineering
- Data warehousing


One of the largest online shops in the Netherlands wanted to develop a standardised way of data processing within one of its data teams. All data was stored in the scalable cloud data warehouse Google BigQuery. Large amounts of data were available within this platform regarding orders, products, marketing, returns, customer cases and partners.
Using Google BigQuery made the data highly accessible to the entire organisation. Data Analysts were responsible for modelling the data using SQL. The output of these SQL queries came in the form of aggregated tables that Business Analysts and Managers used to extract insights.
Within the team, everyone had their personal way of working in an isolated environment. This made it challenging to ensure a standardised working method where everyone performed data transformations in a similar fashion. The following challenges arose as a result:
- No singular source of truth: Requesting figures from Data Analyst A gave different results than those from Data Analyst B.
- No version control: It was unclear who was working, when, and with which code.
- Suboptimal collaboration: Code written by Data Analyst A should theoretically be reusable by Data Analyst B.However, as there was no oversight, this did not occur.
The online shop enlisted our help to fix this. We assembled a team consisting of an Analytics Engineer and a Data Engineer. The Analytics Engineer was responsible for modelling and standardising data and investigating the business's data needs. The Data Engineer was responsible for setting up the cloud environment and the CI/CD pipelines.
Approach
We developed the data transformations in BigQuery using dbt (data build tool). This tool allows Data Analysts and Engineers to transform data in warehouses programmatically and effectively. In the process, dbt provides the ability to apply testing to data models effectively, quickly, and on a large scale. This allows you to check whether the assumptions made about the data are correct.
Step 1 - Inventory: Our Analytics Engineer investigated which data transformations were currently taking place. He then prioritised which tables needed to be modulated via dbt first, resulting in a roadmap.
Step 2 - Setting up cloud components: The Data Engineer created a new Google Cloud environment with a BigQuery data storage and processing component. In addition, he implemented an Airflow instance so that data transformations were performed on a scheduled basis. In doing so, he set up a GitLab environment for collaborative code development. Here he also set up a CI/CD pipeline for automatic testing of the code. This included checks for the presence of documentation and for errors in the code syntax.
Step 3 - Setup and configuration of dbt: We performed the setup and configuration based on the roadmap. We divided the SQL code into reusable modules so that it could be used in multiple issues. We also implemented automatic data testing on the different models. This way, we identified data quality issues in time.
Step 4 - Team training: After the technical implementation, training the team to use the new tooling and guiding them along the new working method was important. To do this, we drew up, among other things, a document outlining the 'new' working method. We also trained them on the following topics:
- Collaboration in GitLab: Gitlab is an efficient way to develop code together with version control.We applied the 4-eyes principle for adding new code.
- Learning to work with dbt: Dbt is a new tool for the web shop's Data Analysts.It allows data to be transformed efficiently, so it is crucial that the team knows exactly how the tool works.
By training the employees on the above topics, they were able to start working with the new modular way of processing data themselves.
Data Architecture
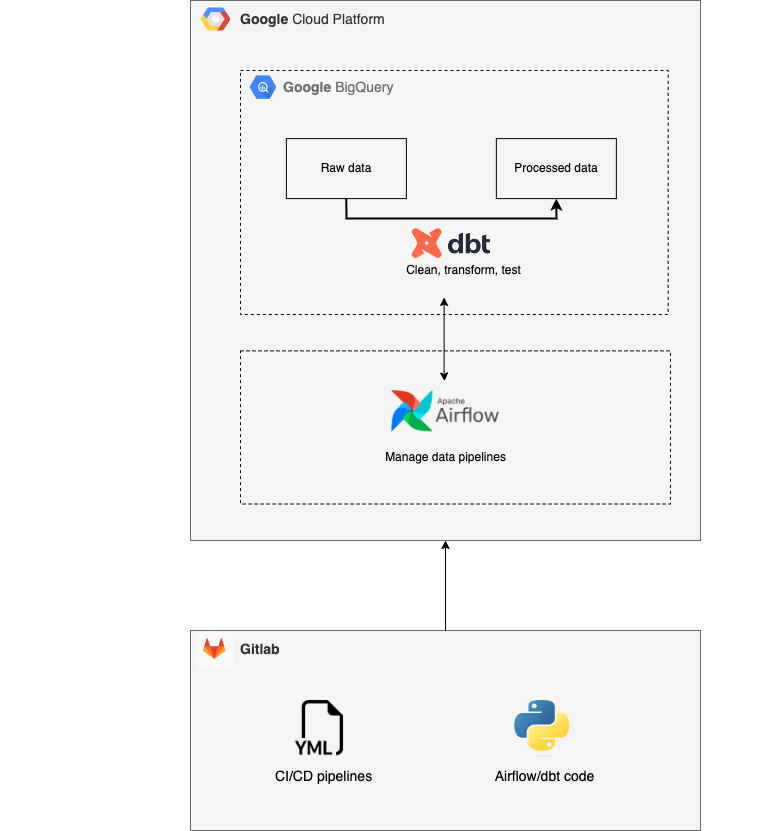
Results
The web shop's Data Analysts can now work together more efficiently and quickly transfer work to each other. Because the SQL code is divided into several separate modules and these are tested automatically, errors are caught at an earlier stage.
In addition, using GitLab ensures version control. This makes it clear who is working with which code and when.
Data quality has significantly increased. Because there is now a single source of truth, Business Analysts and Managers have more confidence in the accuracy of the figures.
Want to know more?
Joachim will be happy to talk to you about what we can do for you and your organisation as a data partner.
Commercieel Manager Data Engineering+31(0)20 308 43 90+31(0)6 23 59 83 71joachim.vanbiemen@digital-power.com
Receive data insights, use cases and behind-the-scenes peeks once a month?
Sign up for our email list and stay 'up to data':