Verbeterde datakwaliteit dankzij een nieuwe data pipeline
Waterschap Aa en Maas:
- Klantcase
- Data Engineering
- Dataconsultancy
- Dataprojecten



Royal HaskoningDHV ziet het aantal aanvragen van klanten met Data Engineering vraagstukken toenemen. De nieuwe afdeling die ze hiervoor op hebben gericht, is nog groeiende. Ze vroegen ons daarom hun Data Engineering team tijdelijk extra capaciteit te bieden. Één van de vraagstukken waar wij hulp bij boden, was die van Waterschap Aa en Maas.
De hydrologen van Waterschap Aa en Maas maken voor hun werk gebruik van veel verschillende databases. Één van die databases bevat data van sensormetingen, bijvoorbeeld van het waterpeil op verschillende plekken in de regio. Het was niet zeker of deze data altijd klopte. Ze vroegen Royal HaskoningDHV een validatieslag te maken en de datakwaliteit op orde te brengen. Zo kunnen de sensormetingen verbeterd worden en kan het Waterschap defecte sensoren repareren.
Onze aanpak
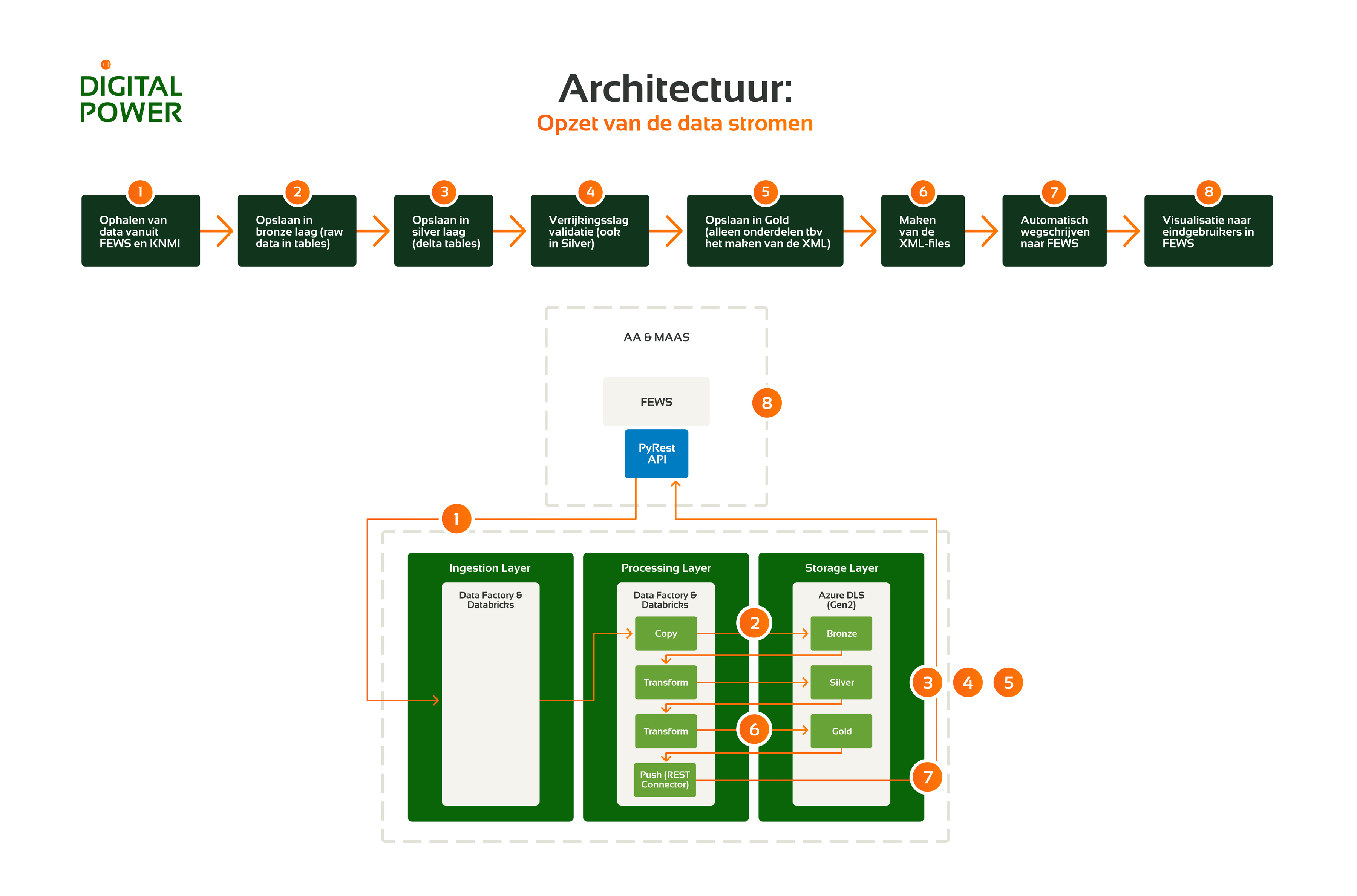
Waterschap Aa en Maas had al de beschikking over een dataplatform in Azure. In opdracht van Royal HaskoningDHV ontwikkelden we een extra data pipeline die met het bestaande platform geïntegreerd kan worden.
We startten met de ontsluiting van de data uit de database via Azure Data Factory. Hiervoor maakten we gebruik van het gelaagde systeem in het data lake. Via de drie lagen bronze, silver en gold wordt de ruwe data steeds verder opgeschoond en verrijkt:
- In de bronze laag maken we de data bruikbaar voor de structuur van het bestaande dataplatform. Dit houdt in dat de ruwe data wordt omgezet naar een tabelstructuur. Hiervoor gebruikten we Databricks en programmeerden we in PySpark.
- In de silver laag valideren we de datakwaliteit. Hiervoor gebruiken we een Python library gemaakt door RHDHV. Deze bevat meerdere data science componenten, waaronder een functionaliteit om data validatie uit te voeren. We verzamelen de data van 90 sensoren die elk kwartier een meting doen. Op elk van die metingen worden zes kwaliteitslabels toegevoegd. Hiermee worden er naar zes mogelijke problemen met de data gekeken. Staat één van deze zes labels op true, dan is dit een indicatie dat er iets mis is met de data.
- In de gold laag zetten we de data om naar een XML-format. Zo kan de data weer terug naar de originele database, die enkel data in dit format kan ontvangen. Op deze manier kunnen we de verrijkte data dus toevoegen in de database. De bestanden worden vervolgens verplaatst naar de serving layer van het data lake. De beheerders van de database hebben toegang tot deze laag, zodat ze de verrijkte data op kunnen halen.
Bij de ontwikkeling van de data pipeline pakten we nog een aantal extra zaken op om de robuustheid van de pipeline te vergroten:
- We logden welke sensoren op welk moment door het verrijkingsproces gaan. Zo kun je altijd terugzien wanneer het model gedraaid heeft en welke sensoren en tijdsreeksen gevalideerd zijn.
- We boden inzicht in veranderingen in de metadata van de sensoren. Bij elke run wordt nu de metadata van de sensor data gesplitst en wordt automatisch gecheckt of er iets veranderd is aan de eigenschappen van de sensor (Slowly Changing Dimensions (SCD-II)).
- In het dataplatform wordt de data dagelijks verwerkt. We bouwden een aparte pipeline waarmee het mogelijk is historische data op te halen van specifieke sensoren. Zo is diepgaande analyse ook mogelijk.
Het resultaat
Na het doorlopen van de bronze, silver en gold laag, gaat de data weer terug naar de originele database. De data is dan volledig gevalideerd en verrijkt. De klant kan precies zien welke data helemaal goed is en welke data fouten kan bevatten.
RoyalHaskoning DHV bewees dat het technisch mogelijk is de datakwaliteit van Waterschap Aa en Maas op orde te brengen. Hier leverden wij een belangrijke bijdrage aan. We testten de pipeline voor 90 sensoren en bouwden een volledig schaalbaar proces zodat er in de toekomst makkelijk opgeschaald kan worden.
Meer weten?
Joachim gaat graag met je in gesprek over wat we als datapartner voor jou en je organisatie kunnen betekenen.
Commercial Manager Data Engineering020 308 43 9006 23 59 83 71joachim.vanbiemen@digital-power.com
1x per maand data insights, praktijkcases en een kijkje achter de schermen ontvangen?
Meld je aan voor onze maillijst en blijf 'up to data':