A scalable machine-learning platform for predicting billboard impressions
The Neuron
- Customer case
- Data Engineering
- Data projects



The Neuron provides a programmatic bidding platform to plan, buy and manage digital Out-Of-Home ads in real-time. They asked us to predict the number of expected impressions for digital advertising on billboards in a scalable and efficient way.
Our approach
Our work consisted of three parts: setting up a data lake in AWS, processing data, and developing, training and implementing a machine-learning model.
Data Lake in AWS
We started with setting up a data lake. You can store large amounts of structured and unstructured data with a data lake. Nowadays, organisations use a wide variety of applications that generate large amounts of data in various formats.
For The Neuron, we set up a data lake with S3 for data storage, Glue Catalog for metadata management and Glue Jobs (managed Apache Spark jobs) for data processing. The data lake is divided into three layers:
- Bronze for raw, unprocessed data.
- Silver for processed data.
- Gold for fully processed and enriched data.
By using serverless AWS components, we ensured good scalability and stability of the platform and lower operational costs. Using Terraform, we developed and implemented all infrastructure with Infrastructure as Code (IaC).
Collect data from cameras
Each billboard is equipped with a camera. The continuous stream of images is collected by a third-party service that uses object detection algorithms to measure the number of people and vehicles passing by.
The raw data is extracted from this service every 5 minutes and stored in a CSV format in the bronze layer of the data lake. The data is then processed and stored in an Apache Parquet format in the silver layer of the data lake. As a final step, the data is aggregated so that it is ready for use within the Machine Learning model. The aggregated data is then stored in the gold layer of the data lake. All processing steps are performed using Apache Spark.
Model development, training and implementation
Het doel van het project was om het aantal billboard-impressies over een The project's objective was to be able to predict the number of billboard impressions over a certain period. To increase the model's accuracy, each billboard was given its own trained version of the model. This meant training a separate model for a total of 140 billboards.
Result
We used AWS Sagemaker to train multiple Machine Learning models simultaneously. The resulting models were stored in S3. The models were then made available via a REST API, from where predictions are retrieved and made available to the bidding platform.
Expected impressions for the next twenty minutes are predicted for each billboard and presented to potential buyers via the exchange platform.
Future
Besides integrating data from cameras, we set data pipelines to process and make data available regarding weather conditions around billboards. In the future, this data can contribute to a further improvement in the accuracy with which the number of expected impressions is predicted.
Want to know more?
Joachim will be happy to talk to you about what we can do for you and your organisation as a data partner.
Business Manager+31(0)20 308 43 90+31(0)6 23 59 83 71joachim.vanbiemen@digital-power.com
Receive data insights, use cases and behind-the-scenes peeks once a month?
Sign up for our email list and stay 'up to data':
You might find this interesting too:
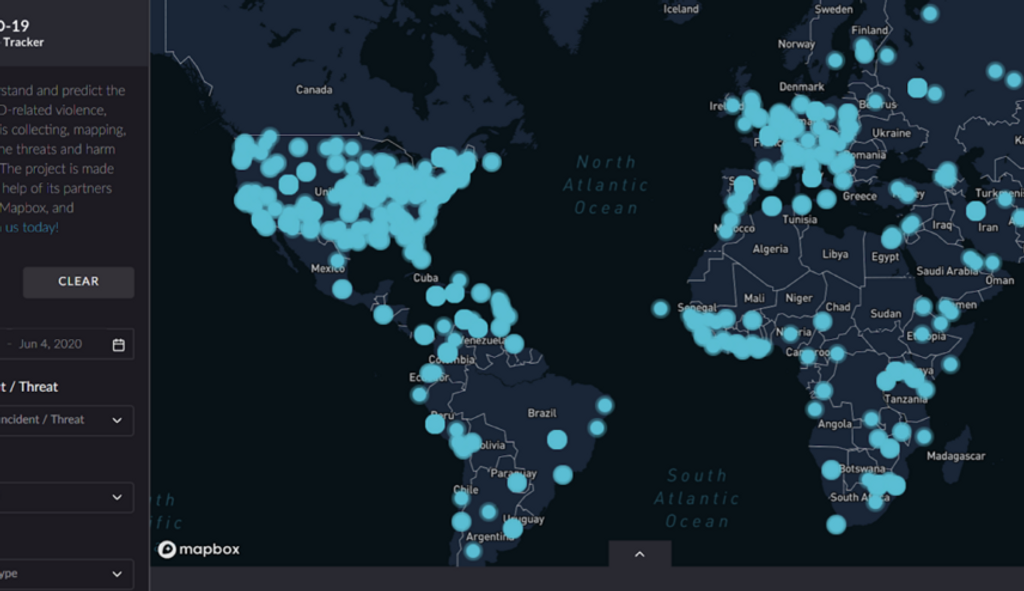
The COVID-19 Violence Tracker
The outbreak of the corona pandemic in early 2020 has turned the world upside down. In addition to countless infections, hospitalisations and deaths, we also saw an outbreak of violence in many countries. Citizens took to the streets, sometimes violently, to protest against the measures taken, but domestic violence also increased in many places and fear and frustration played a role in racism.

Your Data Engineering partner
Generate reliable and meaningful insights from a solid, secure and scalable infrastructure. Our team of 25+ Data Engineers is ready to implement, maintain and optimise your data products and infrastructure end-to-end.
A well-organised data infrastructure
FysioHolland is an umbrella organisation for physiotherapists in the Netherlands. A central service team relieves therapists of additional work, so that they can mainly focus on providing the best care. In addition to organic growth, FysioHolland is connecting new practices to the organisation. Each of these has its own systems, work processes and treatment codes. This has made FysioHolland's data management large and complex.


Implementing a data platform
Based on our know-how, the purpose of this blog is to transmit our knowledge and experience to the community by describing guidelines for implementing a data platform in an organisation. We understand that the specific needs of every organisation are different, that they will have an impact on the technologies used and that a single architecture satisfying all of them makes no sense. So, in this blog we will keep it as general as we can.

Improved data quality thanks to a new data pipeline
At Royal HaskoningDHV, the number of requests from customers with Data Engineering issues continue to climb. The new department they have set up for this, is growing. So they asked us to temporarily offer their Data Engineering team more capacity. One of the issues we offered help with involved the Aa en Maas Water Authority.

Making impact measurable
The Designathon Works foundation organises Design Hackathons (Designathons) for children aged 8 to 12. The target? Teaching children from all over the world skills to become a 'changemaker'. They are challenged to design solutions for a better world, for example to combat climate change. From the Datahub, we helped Designathon Works fine-tune the impact measurements free of charge. We also made a first move towards automating data collection, analysis and visualisation.