Social listening in de vastgoedmarkt
Vesteda
- Klantcase
- Data Science
- Dataprojecten


Vesteda was benieuwd of social listening – het monitoren en analyseren van sociale media-discussies over een merk, concurrenten, producten of hashtags/zoekwoorden – waarde kon toevoegen aan de organisatie. Hiervoor startten we een project dat bestond uit twee onderdelen: het verkennen van mogelijkheden voor social listening op de afdeling Corporate Communicatie en het toepassen van social listening in een lopend Data Science-project.
Onze aanpak
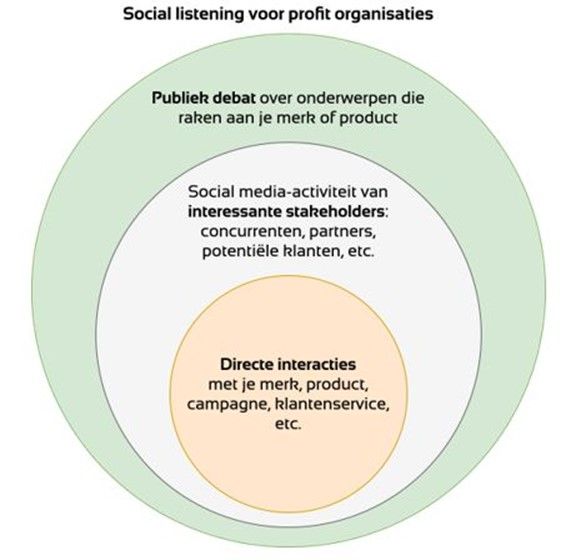
Mogelijkheden voor social listening op de afdeling Corporate Communicatie
Vesteda heeft al tools in gebruik voor social listening, namelijk Meltwater en Hootsuite. Met behulp van Meltwater verzamelt Vesteda data over verschillende thema’s, zoals de “Nederlandse woningmarkt” en “Maatschappelijk Verantwoord Ondernemen”.
We plotten de bestaande infrastructuur op de drie niveaus van social listening en gingen op zoek naar kansen voor verbetering. Een voorbeeld hiervan is de zoekopdracht “Nederlandse woningmarkt” in het segment online media: deze zoekopdracht hoort op het niveau ‘publiek debat’. Hier ontdekten we dat er op publiek niveau alleen werd gekeken naar online media en nog niet naar sociale media.
Om sneller in te kunnen spelen op discussies over bijvoorbeeld duurzame woningbouw, adviseerden we een zoekopdracht toe te voegen die naast online media ook kijkt naar sociale media.
Gebruik van social listening binnen een Data Science-project
Naast verkennend onderzoek over de mogelijkheden van social listening, pasten we de methode tegelijkertijd toe in het ‘buurtscore-project’. Het doel van dit project is het ontwikkelen van een voorspellend model voor de investeringspotentie van buurten.
Zo’n model kan, als het succesvol blijkt, worden gebruikt als ondersteuning voor het selecteren van buurten om in te investeren. Het model bestaat uit verschillende variabelen die samen een buurtscore vormen.
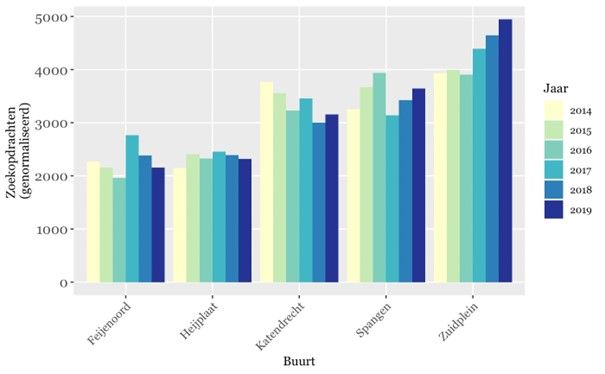
Aan dit model voegden we in een pilot twee nieuwe variabelen toe: Google-zoekgedrag naar een buurt en het aantal Instagram-posts vanuit een buurt. Beide variabelen kunnen een indicatie zijn van interesse in buurten.
Hieronder zijn bijvoorbeeld de zoekopdrachten naar vijf buurten in Rotterdam gevisualiseerd in de periode van 2014 tot 2019:
Het resultaat
We presenteerden ons werk en advies in een rapport aan het Data Science-team en de afdeling Corporate Communicatie van Vesteda. Daarmee kunnen de teams zelf aan de slag met social listening. De social listening-data is uiteindelijk niet gebruikt in het Buurtscore-model, maar leverde wel nieuwe inzichten: Google-zoekgedrag naar- en Instagram posts vanuit een buurt waren geen verklarende factor voor het oordeel van experts over de potentie van een buurt. Ook dat is een resultaat!
Daarnaast leerde het Data Science-team van de verschillen in hoeveelheid social listening–data per buurt.
Meer weten?
Business Manager Joachim gaat graag met je in gesprek over wat we als datapartner voor jou en je organisatie kunnen betekenen.
Business Manager020 308 43 9006 23 59 83 71joachim.vanbiemen@digital-power.com
1x per maand data insights, praktijkcases en een kijkje achter de schermen ontvangen?
Meld je aan voor onze maillijst en blijf 'up to data':